Biased estimators: focus on dispersion indicators
14/03/2023

One of the aims of a statistical study is to estimate quantities (e.g., mean, variance, standard deviation, etc.) that can be used to describe a population in order to study its characteristics. To estimate these quantities, it is necessary to define mathematical functions called estimators. These estimators are then applied to sample data from the study population. For example, if we want to estimate the mean age of patients in a study population (denoted ![]() ), we use the arithmetic mean estimator, where X is the random variable representing the age of patients:
), we use the arithmetic mean estimator, where X is the random variable representing the age of patients:
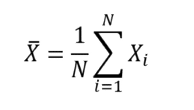
Estimation of the variance of a random variable
To continue with the previous example, let’s imagine that the objective is to estimate the variance of the age of patients in the population. To do this, we need to construct a variance estimator. A first proposal would be to naively estimate the variance using the following estimator:
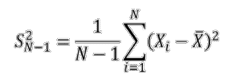
It is possible to show that this estimator is in fact biased, despite its intuitive appearance. The following variance estimator is then proposed:
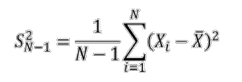
This estimator can be shown to be an unbiased estimator of the variance of the age of patients in the study population*.
To illustrate this, simulations were carried out. The following graph shows the estimations for different sample sizes considered.

The results show that for small sample sizes (less than or equal to 10) the bias of the naive variance estimator can be quite high. However, for larger sample sizes (greater than or equal to 100) the bias becomes negligible. The corrected variance estimator is always unbiased, whatever the sample size. Since correcting the estimator is not complex, it is a good idea to keep this corrected estimator, whatever the sample size.
Estimation of the standard deviation of a random variable
It has already been shown that the S²_(N-1) estimator is an unbiased estimator of the variance of a random variable. To estimate the standard deviation, it would then be tempting to calculate √(S²_(N-1)). However, it can be shown that √(S²_(N-1)) is a biased estimator of the standard deviation in the population.
It is also possible to demonstrate that √(S²_N) should be an even more biased estimator *.
Unlike the variance estimator, it is impossible to define a standard deviation estimator which is unbiased, whatever the distribution of the variable X. However, in the case where X follows a normal distribution, the bias of √(S²_(N-1)) can be expressed. This is a multiplicative bias denoted c₄(N) by convention*.
Thus, if X follows a normal distribution, it is possible to calculate the following unbiased estimator :
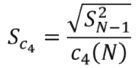
To illustrate the three standard deviation estimators presented above, a simulation study similar to the previous one was carried out. The following graph shows the estimates for the different sample sizes considered.

The results show that for small sample sizes (less than or equal to 10) the bias of the √(S²_(N-1)) estimator can be quite high. However, for larger sample sizes (greater than or equal to 50) the bias becomes negligible. The estimator corrected for standard deviation (by the quantity c₄(N)) is always unbiased, whatever the sample size. The ![]() , estimator is of no interest because it is always more biased than √(S²_(N-1))
, estimator is of no interest because it is always more biased than √(S²_(N-1))
.
The correction of the estimator is made through a complex quantity (c₄(N)), that is why the biased estimator of the standard deviation is retained for large sample sizes, but it is important to correct for small sample sizes.
Conclusion
The aim of this brief article is to raise aware of the notion of bias in an estimator, and to remind everyone to be vigilant. The example of the estimator of the standard deviation demonstrates quite effectively that intuitions can sometimes play tricks in statistics.
*Demonstration available on request
For further information on the longer version of this article, contact our experts at solutionprojectdelivery@efor-group.com
Efor group
Our CSR commitments
Aware of our social and environmental responsibility, we act every day to make a positive impact on society.
Our news
Discover all our technical articles and news
-
 Technical articles
Technical articles16/07/2026
Validating Cloud & SaaS Solutions in GxP-Regulated Environments: Shared Responsibility, Vendor Qualification, and Continuous Compliance
As more and more healthcare manufacturers adopt these technologies, they must remain particularly vigilant about how this choice a
-
 News
News9/07/2026
Efor launches Valimate, its artificial intelligence platform dedicated to compliance and validation in Life Sciences
Efor Valimate, the new artificial intelligence platform developed by Efor to support CQV professionals.
-
 News
News2/07/2026
Efor and TIME France unveil the first edition of the TIME France Health awards
We are proud to unveil the results of the first edition of the TIME France Health awards, created by TIME France in partnership wi