Impact of a logarithmic transformation of the response variable in an ANCOVA model
17/05/2023

Logarithmic transformations of variables have traditionally been used to study analytical measurements in clinical and industrial studies. Indeed, the distribution of many biological data measurements is right-skewed and/or has a variability that increases as the mean increases. A logarithmic transformation often returns a normal, homoscedastic distribution (Cf. European Pharmacopoeia, chapter 5.3 Statistical analysis of results of biological assays and tests).
It is important to ask why this transformation is necessary, how it should be applied and what the consequences are in terms of interpretation. This short article presents the case of logarithmic transformations with any base, and their impact when calculating mean and when calculating predictions of a model.
For the rest of this article, we will take the example of a stability analysis, which involves regularly performing analytical measurements on several batches over time.
We’ll look at the consequences of such a transformation if we wish to predict the arithmetic mean of Y.
Differences between arithmetic and geometric means
Before going any further on this subject, it’s important to review what arithmetic and geometric means are.
The arithmetic mean is the best-known and most widely used term for “mean”. It is defined as:
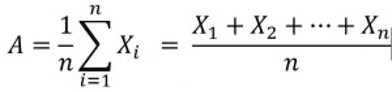
where X is any random variable.
The geometric mean also aims to give the central tendency of a variable, but instead of using the sum of this variable, it uses its product:
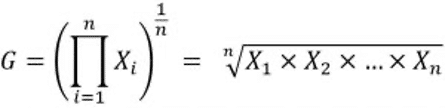
The following formula can also be used:
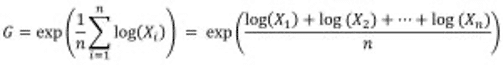
It can be shown* that the geometric mean G is always less than or equal to the arithmetic mean A.
The second expression for the geometric mean is interesting because it is the mean of the logarithmic values of X to which we apply the exponential function. This expression will be useful to us later, particularly for understanding the impact of a logarithmic transformation on the estimation of the mean of a given variable.
Note: The geometric mean is suitable for biological data that follow a log-normal distribution. It is always less than or equal to the arithmetic mean.
Impact of a base b log transformation of Y in an ANCOVA model for predicting the arithmetic mean of Y
The objective is to model the evolution of any quantity (Y) over k batches over time (T). The model classically recommended for this type of analysis is an ANCOVA-type model expressed as follows:
Yᵢⱼ = ηᵢ + γᵢ Tᵢⱼ + rᵢⱼ
with η = (η₁, …, η_k)’ is the vector of parameters of the ordinates at the origin of each batch,
γ = (γ₁, …, γ_k)’ is the vector of slope parameters of each batch and rᵢⱼ ~ N(0, σ_r²) is the random error of the model assumed to follow a normal distribution with expectation 0 and variance ![]() .
.
When the assumption of normality of the residuals is not respected, it is conventional to transform the variable Y in such a way that Z = g(Y), with g(.) is the function of the transformation chosen, and to adjust an identical model to the variable Z.
We take here the case of the base b logarithmic transformation such that:
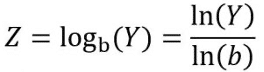
In this case, Z can be modelled using an ANCOVA model in the same way as described above:
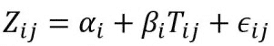
with εᵢⱼ ~ N(0, σ_ε²). Note that in this example, the logarithmic transformation is applied only to Y and not to the time variable T.
An equation is calculated and then predictions of Zᵢⱼ (with their confidence intervals) are usually calculated. To make them scientifically exploitable, an inverse transformation is regularly applied to bring the predictions back into the initial data:
Yᵢⱼ = b^(Zᵢⱼ) = exp(ln(b) × Zᵢⱼ).
However, this approach introduces a bias in the predictions of which we must be aware and which we may or may not accept.
Explanations: as Yᵢⱼ = exp(ln(b) × Zᵢⱼ), it would be tempting to apply this same naive formula to the mean prediction of Zᵢⱼ at a given time (denoted E[Yᵢⱼ | Tᵢⱼ]), to calculate the arithmetic mean of the prediction of Yᵢⱼ (denotedE[Yᵢⱼ | Tᵢⱼ]). However, it is possible to demonstrate* that this formula is false when applied to the mean prediction of Zᵢⱼ. This means that:
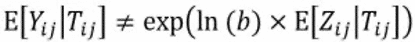
In other words, the prediction calculated with the data without transformation is not equal to the prediction of the model on the transformed data, after inverse transformation. In fact, exp(ln(b) × E[Zᵢⱼ|Tᵢⱼ]) corresponds to the geometric mean of the prediction of Yᵢⱼ, hence the observed difference.
If we want to calculate the arithmetic mean of the prediction of Y, we need to use the following formula*:
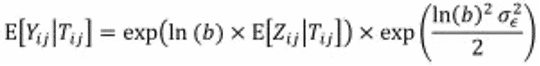
We conclude that the naive formula has a multiplicative bias denoted B = 1 / exp((ln(b)² × σ_ε²) / 2) which means that the naive formula divides the true arithmetic mean by a quantity equal to exp((ln(b)² × σ_ε²) / 2). This multiplicative bias is a function of: :
- b, the base of the logarithmic transformation performed,
- σ_ε², the residual variance of the model fitted to Z, the log-transformed variable. As a reminder, σ_ε² measures the variance that is not explained by the model (Mean Square Error). Theoretically, √(σ_ε²) = σ_ε should be of the same order of magnitude as the standard deviation of the measurement method.
The following graph shows the value of the bias B as a function of the residual variance of the model in the case of a base 10 logarithmic transformation.
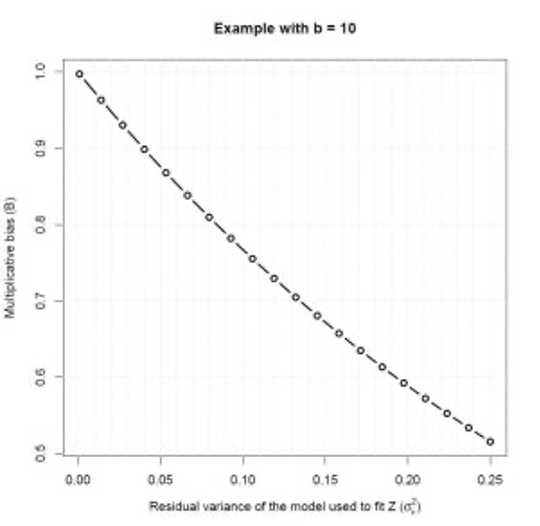
The graph shows that the smaller the residual variance, the smaller the bias. Thus, if the residual variance is low (σ_ε²<0.025) then the bias is low too in the estimation of the arithmetic mean using the naive formula. On the other hand, when the residual variance increases, the estimation of the arithmetic mean of Yᵢⱼ is greatly affected. For example, when σ_ε²=0.25 then the estimate of the arithmetic mean of Yᵢⱼ by the naive formula is about half (B=1/0.5) the true arithmetic mean.
Thus, when a transformation has been applied for practical reasons (ANCOVA prerequisites not met) and the data are not routinely transformed, it is recommended to take this bias into account, even for low residual variances, or to express the prediction results with the model established on the untransformed data.
Note: applying an inverse transformation to the predictions of a model processed in logarithm gives “geometric predictions”, not “arithmetic predictions”.
Conclusion
A transformation of the variable Y is not a trivial action if the initial objective is to estimate the arithmetic mean of Y.
When the data analysed intrinsically has a lognormal distribution, the need to correct for this bias is debatable; in fact, the predicted values are “geometric predictions” that are consistent with the lognormal distribution of the data.
When the transformation has been applied for practical reasons (ANCOVA prerequisites not met) and the data are not usually transformed, the proposed approach is to correct the predictions by the B factor, or not to transform the data.
Therefore, it is important to be aware of the impact of such a transformation when considering the desired objective (either estimating the arithmetic mean of Y or estimating its geometric mean).
For further information on the longer version of this article, please contact our experts at solutionprojectdelivery@efor-group.com
*Demonstration available on request.
Efor group
Our CSR commitments
Aware of our social and environmental responsibility, we act every day to make a positive impact on society.
Our news
Discover all our technical articles and news
-
 Technical articles
Technical articles16/07/2026
Validating Cloud & SaaS Solutions in GxP-Regulated Environments: Shared Responsibility, Vendor Qualification, and Continuous Compliance
As more and more healthcare manufacturers adopt these technologies, they must remain particularly vigilant about how this choice a
-
 News
News9/07/2026
Efor launches Valimate, its artificial intelligence platform dedicated to compliance and validation in Life Sciences
Efor Valimate, the new artificial intelligence platform developed by Efor to support CQV professionals.
-
 News
News2/07/2026
Efor and TIME France unveil the first edition of the TIME France Health awards
We are proud to unveil the results of the first edition of the TIME France Health awards, created by TIME France in partnership wi